Geoclassifier-Granule.ai
Brief Overview of Problem Statement
The goal of this challenge is to classify a given geographical feature into one of the six classes.
- ‘Demolition’: 0
- ‘Road’: 1
- ‘Residential’: 2
- ‘Commercial’: 3
- ‘Industrial’: 4
- ‘Mega Projects’: 5
Dataset Analysis
The dataset consisted of training and test data. Both the datasets were in .geojson format. The problem statement requires to use CVPR EarthVision dataset. The entire description of the dataset and usage of different Deep Learning technics to produce it can be found on the attached link.
Total Entries: 310006
Columns: 15
Index([‘index’, ‘change_type’, ‘change_status_date1’, ‘change_status_date2’, ‘change_status_date3’, ‘change_status_date4’, ‘change_status_date5’, ‘date1’, ‘date2’, ‘date3’, ‘date4’, ‘date5’, ‘urban_types’, ‘geography_types’, ‘geometry’], \
Independent Variables:
- change_status
- urban_types
- geography_types
- geometry
Dependent Variable:
- change_type
From the above, urban_types and geography_types are multi valued categorical columns, thus need to convert them into numeric. Thus, use One Hot Encoding. Geometry can used to find area or perimeter of the polygon. The difference between the two dates can also be used to predict the contruction type at the place.
I have used geometry, urban_types and geography_types as independent variables and have dropped change_status.
Development Environment
- Kaggle(primary)
- Jupyter Notebook(secondary)
Model training and submission
Major Libraries used:
- numpy = linear algebra
- pandas = fileprocessing(I/O operation)
- geopandas = process geospatial data
- sklearn = labelencoding, one hot encoding, KNeighborsClassifier
- gradio = implement GUI for trained model.
As per the instructions in kaggle, I have used KNeighborsClassifier to train dataset with value of k=3.
Used geopandas to read data from train.geojson and test.geojson. The geography_types had multiple parameters separated by , which had roughly 100 unique entries, which means 100 bits in one hot encoding which would take significant processing power, and stale the output. To avoid this, I took only the first occurence which reduced the entries to 15.
df_geography = df['geography_types']
df_geography_single = []
#df_geography[0]
for i in range(len(df_geography)):
df_geography_single.append(df_geography[i].split(",", 1)[0])
Same is true with urban_types. Reduced number of entries to five.
Now, use the One Hot Encoding to convert string to numeric value.
df_demo = get_ohe(df_demo)
ohe = OneHotEncoder(sparse=False)
ohe.fit((df_demo['geography_types'].values.reshape(-1, 1)))
def get_ohe(df):
temp_df = pd.DataFrame(data=ohe.transform(df[['geography_types']]), columns=ohe.get_feature_names_out())
df.drop(columns=['geography_types'], axis=1, inplace=True)
df = pd.concat([df.reset_index(drop=True), temp_df], axis=1)
df
return df
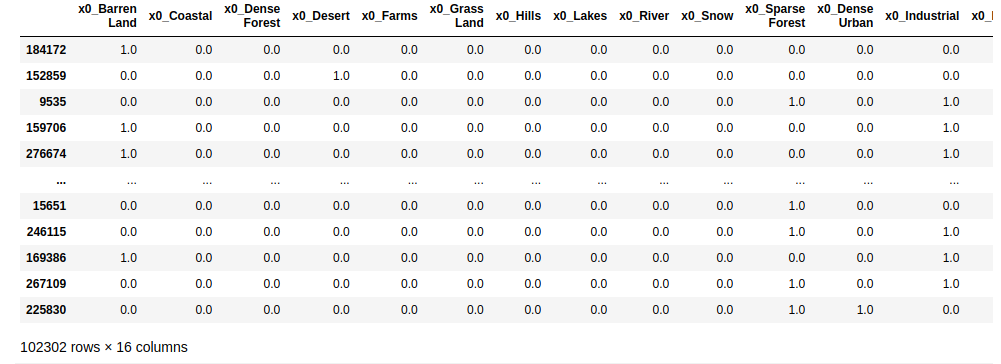
Repeat same procedure for urban_types. We get the following output:
Using labelencoding, convert the given change_types classes corresponding Integer.
- ‘Demolition’: 1
- ‘Road’: 5
- ‘Residential’: 4
- ‘Commercial’: 0
- ‘Industrial’: 2
- ‘Mega Projects’: 3
encoded_change = le.fit_transform(df_demo['change_type'])
le = preprocessing.LabelEncoder()
le.fit(["Demolition", "Road", "Residential", "Commercial", "Industrial", "Mega Projects"])
list(le.classes_)
Use sklearn train_tes_split to split and train the model with train_size as 0.67. The accuracy of the model roughly came out to be 45%.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.67)
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(X_train, y_train)
prediction_train = neigh.predict(X_test)
mean_f1_score:
from sklearn.metrics import precision_score, recall_score
p = precision_score(y_test.values, prediction_train, average = "micro")
r = recall_score(y_test.values, prediction_train, average="micro")
mean_f1_score = (2*(p*r))/(p+r)
Integrating with Grad IO
Grad IO provides a simple to integrate GUI development platform.
import gradio as gr
def image_classifier(inp):
return {'cat': 0.3, 'dog': 0.7}
demo = gr.Interface(fn=image_classifier, inputs="image", outputs="label")
demo.launch()
Above is the standard code snippet from gradio.app, it has image_classifier function which implements the logic. Part of logic is to predict the output using trained model.
Logic for Geoclassifier: I have maintained a dictionary with keys as the urban_types and geography_types string and value default to 0. Now, change the value to 1 for the specific key passed as input. Then dict.values() convert into 2D array and pass the array to trained model to predict output.
def convert_value(urban, geography):
if urban in areatype.keys():
if geography in areatype.keys():
areatype[urban]=1
areatype[geography]=1
converted=[]
temp=[]
for item in areatype.values():
temp.append(item)
converted.append(temp)
return converted
def predict_value(converted):
prediction = neigh.predict(converted)
return prediction
def convert_to_class(prediction):
return classes[prediction]
def merge(urban, geography):
urban_value = str(urban)
geography_value = str(geography)
converted_arr=[[]]
if urban_value in areatype.keys():
if geography_value in areatype.keys():
converted_arr = convert_value(urban_value, geography_value)
else:
return "Incorrect Input"
else:
return "Incorrect Input"
prediction = predict_value(converted_arr)
class_output = convert_to_class(prediction[0])
return class_output
Hosting Grad IO:
import gradio as gr
outputs = gr.outputs.Textbox()
app = gr.Interface(fn=merge, inputs=['text', 'text'], outputs=outputs, description="GEO: Barren Land, Coastal, Dense Forest, Desert, Farms, Grass Land, Hills, Lakes, River, Snow, Sparse Forest || URBAN: Dense Urban, Industrial, Rural, Sparse Urban, Urban Slum")
app.launch(share=True)
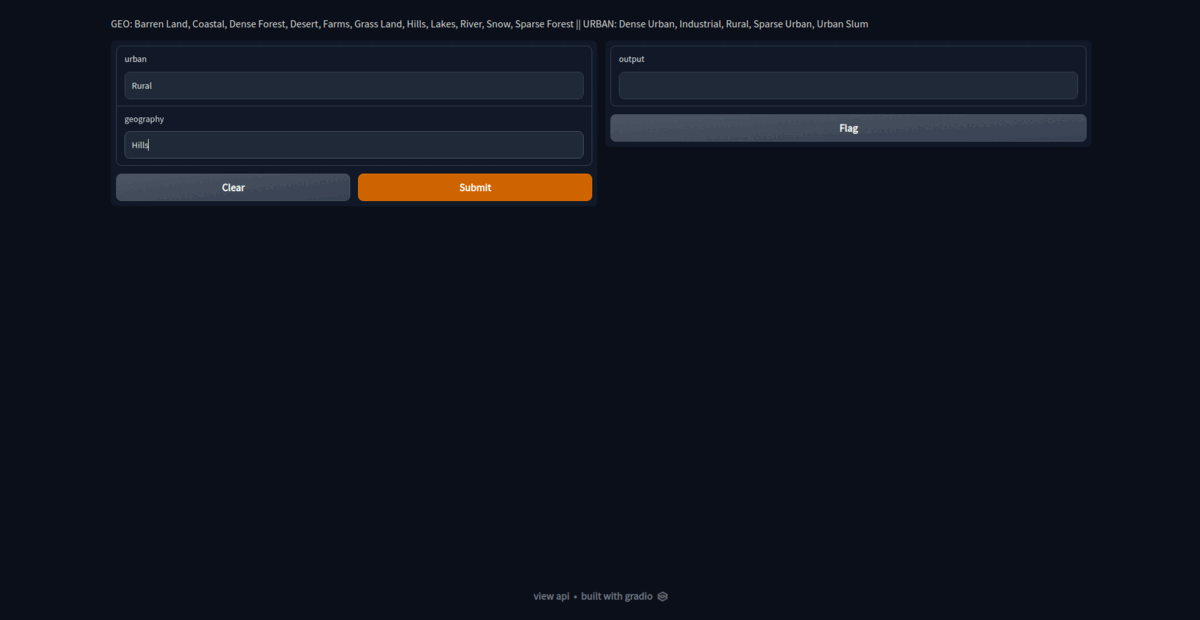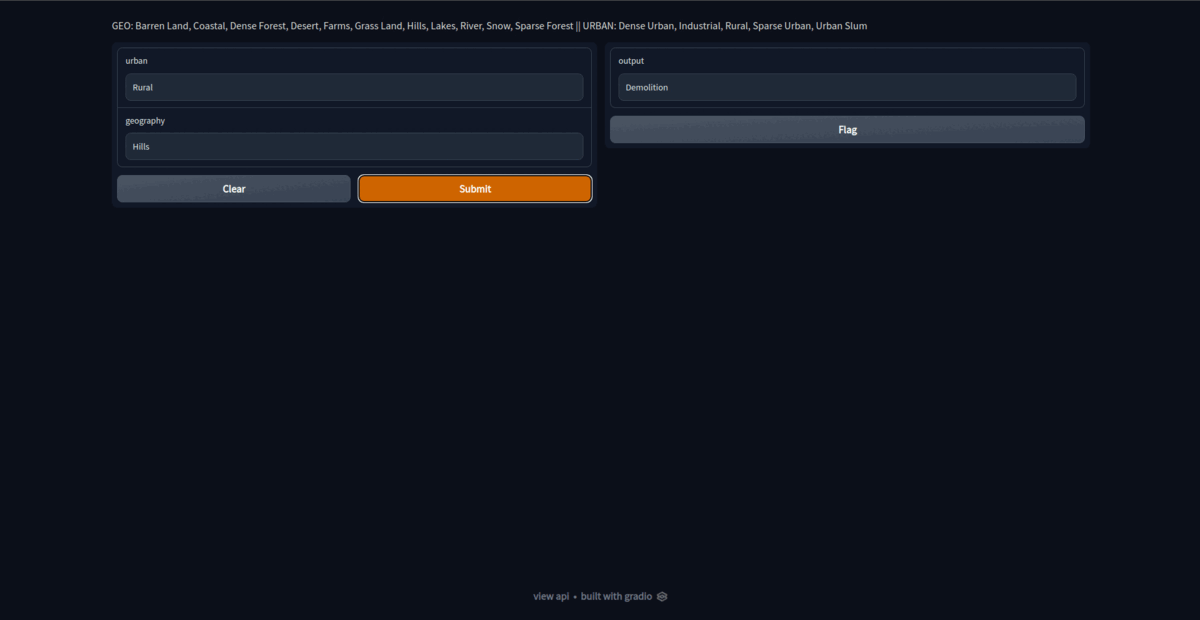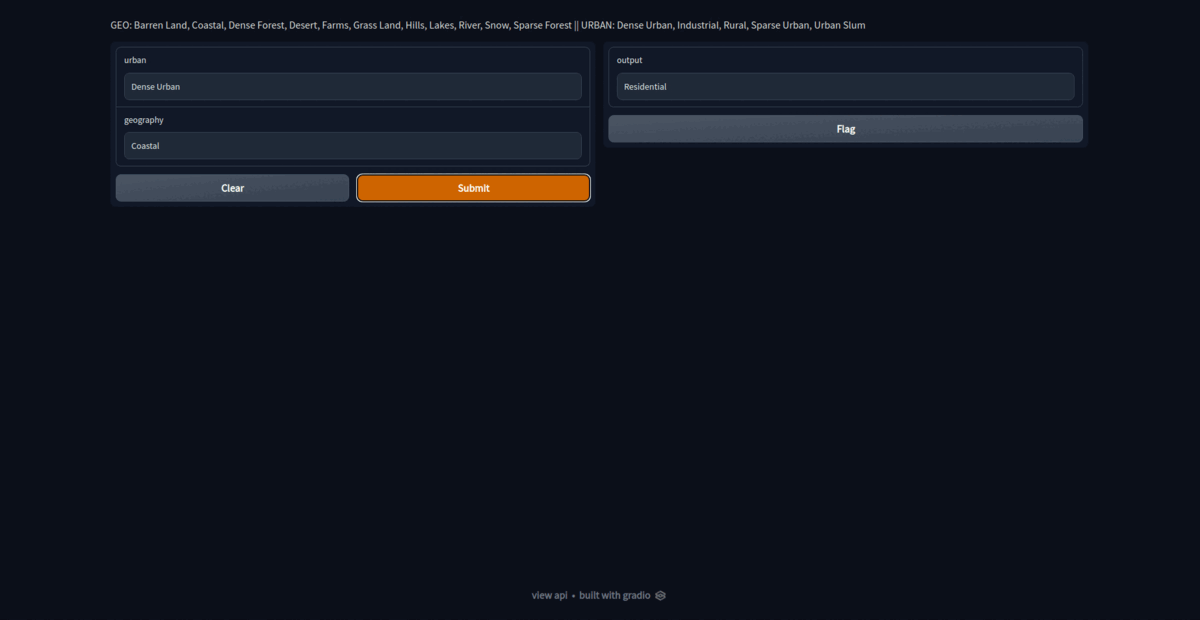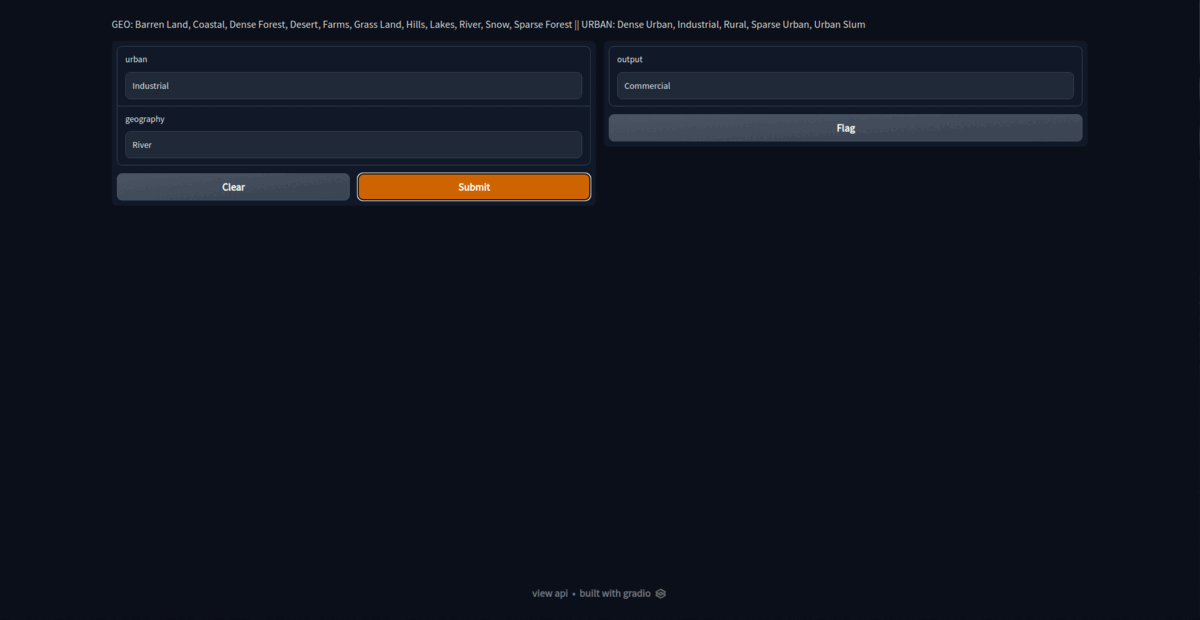
On launching the app, we get https://51381.gradio.app/ as public gradio link. This link would be operation for about 72 hours after hosting for first time. Thus, its a temporary hosting. For permanent hosting, deploy the model on hosting platforms like hugging face.
NOTE:
I tried to include the area of the polygon as the independent variable in training dataset which further increased the accuracy to approximately 49%. I used geopandas to calculate the area of the polygon.
Deployment
Grad IO is compatible with hugging face hosting platform. I tried deploying the model on the hugging space, and was successful in understanding the docs, created new space, added app.py, but there is a environmental issue which is hindering in hosting of the model.
Repository: https://huggingface.co/spaces/7siddhesh4-kanawade3/geoclassifier
Error:
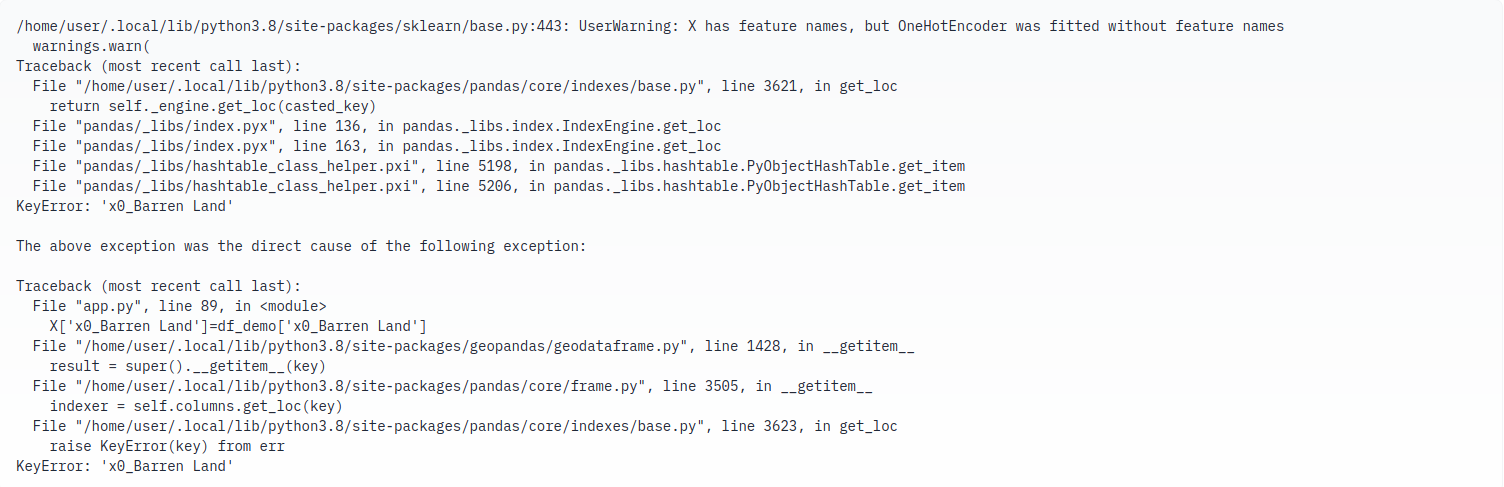
Scope for improvement
- Include area, change_status, dates in prediction
- Don’t split the geography_types and urban_types dataset
- Deploy the model