CS 301: Operating Systems: Assignment 2
Group Members
Siddhesh Kanawade: siddhesh.kanawade@iitgn.ac.in
Kushgra Jain: kushagra.jain@iitgn.ac.in
Utkarsh Mishra: utkarsh.mishra@iitgn.ac.in
Preliminaries
The code is highly self explanatory due to multiple comments and humanly readable variables and function names. The main goal of this assignment was to understand the Userprog in the Pintos Operating System. Also, please note that, the comments in the datastructure section are drafted to act as the description of the struct, enum, or data type.
ARGUMENT PASSING
—- DATA STRUCTURES —-
The present data structures sufficed the requirement of this task and hence no new datastructures were created.
—- ALGORITHMS —-
Argument Passing
Currently, process_execute() does not support passing arguments to new processes. As per requirement, we had to split the input from the command line at spaces and take the first word as program name and the remaining as arguments. Example provided was process_execute(“grep foo bar”) should run grep passing two arguments foo and bar.
To implement this, we have used the strtok_r() function to split the string from the command line, and the obtained words can now be used as the filenames and arguments.
Once we have split the string, and have our file name, we create a new thread, naming it the same as the file name for convenience, call the start_process function with the file name and pass the arguments to load(). and setup_stack().
The arguments and commands are pushed into the stack when the page is initialised.
process_execute:
tid_t
process_execute (const char *file_name)
{
char *fn_copy;
tid_t tid;
/* Make a copy of FILE_NAME.
Otherwise there's a race between the caller and load(). */
fn_copy = palloc_get_page (0);
if (fn_copy == NULL)
return TID_ERROR;
strlcpy (fn_copy, file_name, PGSIZE);
/* Create a new thread to execute FILE_NAME. */
/* Seperate file_name into two parts => fn_argv0 for filename, save_ptr for other arguments */
char *fn_argv0, *save_ptr;
fn_argv0 = strtok_r(fn_copy, " ", &save_ptr);
tid = thread_create (fn_argv0, thread_current()->priority,
start_process, save_ptr);
/* Let parent process wait until the child process successfully loads its executables */
sema_down(&thread_current()->process_wait);
if (tid == TID_ERROR)
palloc_free_page (fn_copy);
return thread_current()->child_load_status;
}
Arranging elememts of argv[] in right order
We parse the strings in the order of last to first, in which the last string will be the command and the first one will be the last argument. For example, if we have run echo x, then the first element would be x and run would be the last argument
Avoiding overflowing the stack page
When overflowing would occur, exit(-1) will be executed and overflowing would be detected. Its basically based on concept of page fault exception.
—- RATIONALE —-
Why does Pintos implement strtok_r() but not strtok()
The strtok_r() function is the restartable version of strtok(). We can use it in nested loops, several threads at once, etc. It returns a pointer which we can use to restart on the same string. We can not do the same with the strtok(). Using it can cause errors and the program could crash.
Why does Pintos implement strtok_r() but not strtok()
In the Pintos approach, the memory needed for parsing arguments is spent by the kernel. This is not advantageous since, if the kernel runs out of memory, the whole system can crash.
In Unix, and shell being a user program, the argument parsing is done in user program memory. So even if the user program memory runs out, system will not crash, unlike Pintos.
Another advantage is that shell can perform checks on the arguments before passing them to the kernel. It can deal with blank lines, invalid characters etc and not send them to the kernel. This is not so in Pintos.
SYSTEM CALLS
—- DATA STRUCTURES —- In threads/threads.h:
struct thread *parent; /* Which thread creates this one. */
struct list children; /* Threads that this one creates. */
struct list_elem child_elem; /* List element for list children. */
int child_load_status; /* Load status of its child*/
int child_exit_status; /* Exit status of its child*/
struct list open_fd; /* Fds the thread opens*/
struct file *file; /* Executable file of this thread. */
struct semaphore process_wait; /* Determine whether thread should wait. */
Describe how file descriptors are associated with open files
Every file is assigned to a unique descriptors, as a number. The fd is a non-negative integer with 0 and 1 as standard input and output respectively, rest all values can be used to allocate the file. The file descriptors are only unique within a process.
—- ALGORITHMS —-
Describe your code for reading and writing user data from the kernel
Step 1: Check if the buffer pointer is in a valid range, if not then exit.
Step 2: Check if the buffer pointer is doing reading operation or writing operation.
Step 3: The descriptor of the threads will acquire a lock and check if standard input or output operation, (STDIN_FILENO or STDOUT_FILENO) is performed. Then perform the read or write operation while holding the lock and release it after the operation is complete.
Suppose a system call causes a full page (4,096 bytes) of data to be copied from user space into the kernel. What is the least and the greatest possible number of inspections of the page table (e.g. calls to pagedir_get_page()) that might result? What about for a system call that only copies 2 bytes of data? Is there room for improvement in these numbers, and how much?
We need to do at least one inspection. One call to pagedir_get_page() is needed. The greatest number of calls needed for the required inspection is 2. Even for a call that copies only 2 bytes of data the operation remains unchanged.
Briefly describe your implementation of the “wait” system call and how it interacts with process termination.
We use the process_wait() function inside the wait function. The child thread found will be allowed to terminate and any resources it held would be relinquished.
process_exit:
/* Free the current process's resources. */
void
process_exit (void)
{
struct thread *cur = thread_current ();
/* If child's parent is still waiting for child,
remove itself from children list of its parent
and stop its parent waiting. */
if (cur->parent != NULL)
{
list_remove(&cur->child_elem);
sema_up(&cur->parent->process_wait);
}
/* Deal with its chidren --
Stop all its children waiting. */
struct list_elem *e;
for (e = list_begin (&cur->children); e != list_end (&cur->children);
e = list_next (e))
{
struct thread *tmp = list_entry (e, struct thread, child_elem);
sema_up(&tmp->process_wait);
}
/* Destroy the current process's page directory and switch back
to the kernel-only page directory. */
uint32_t *pd = cur->pagedir;
if (pd != NULL)
{
/* Correct ordering here is crucial. We must set
cur->pagedir to NULL before switching page directories,
so that a timer interrupt can't switch back to the
process page directory. We must activate the base page
directory before destroying the process's page
directory, or our active page directory will be one
that's been freed (and cleared). */
cur->pagedir = NULL;
pagedir_activate (NULL);
pagedir_destroy (pd);
}
}
Any access to user program memory at a user-specified address can fail due to a bad pointer value. Such accesses must cause the process to be terminated. System calls are fraught with such accesses, e.g. a “write” system call requires reading the system call number from the user stack, then each of the call’s three arguments, then an arbitrary amount of user memory, and any of these can fail at any point. This poses a design and error-handling problem: how do you best avoid obscuring the primary function of code in a morass of error-handling? Furthermore, when an error is detected, how do you ensure that all temporarily allocated resources (locks, buffers, etc.) are freed? In a few paragraphs, describe the strategy or strategies you adopted for managing these issues. Give an example
We prevent this issue by checking the validity of the buffer pointer before allowing any read/ write operations in the system call. We verify if all the arguments of the system call are in user memory instead of kernel memory. Any pointer that is not valid, i.e. it points to either kernel memory or is a null pointer triggers a page fault and is handled by page_fault() in userprog/exception.c. The process is subsequently terminated using sys_exit()
—- SYNCHRONIZATION —-
The “exec” system call returns -1 if loading the new executable fails, so it cannot return before the new executable has completed loading. How does your code ensure this? How is the load success/failure status passed back to the thread that calls “exec”?
When process_execute() is called, it returns the thread id of the thread if the execution was successful. If the value of the status of the thread is “FAILED” then the return value is -1.
The status of any child, i.e. the value of the child_status variable in thread_struct, is updated whenever there is a change in the status of the child thread. The initial status upon creation is LOADING. The status changes upon successful completion. And if it is FAILED then the code does as described above.
Consider parent process P with child process C. How do you ensure proper synchronization and avoid race conditions when P calls wait(C) before C exits? After C exits? How do you ensure that all resources are freed in each case? How about when P terminates without waiting, before C exits? After C exits? Are there any special cases?
- When P waits for C, P has to stop and wait for C to execute and exit. When C exits, the locks acquired by the C are released.
- If P calls wait after C exits, P will check for its children and will find that it has no children to wait for and hence it P won’t wait.
- When P terminates before C exits, all the children of P including C will be killed and they will be terminated and release their locks.
- When P terminates after C exits, C’s locks should be released.
—- RATIONALE —–
Why did you choose to implement access to user memory from the kernel in the way that you did?
Implementing page fault memory handling is difficult than to implement the validate arguments and status for error catching.
Whenever a pointer is invalid, it will be caught by the page fault interrupt handler and the syscall_exit will be called.
What advantages or disadvantages can you see to your design for file descriptors?
File descriptors are unique for each process, thus, it eliminates the race conditions.
The cost of having file descriptors can be high and it can slow down the system.
The default tid_t to pid_t mapping is the identity mapping. If you changed it, what advantages are there to your approach?
We didn’t changed the default tid_t to pid_t mapping. In our current knowledge and capabilities, it was the most optimised way to deal with the situation.
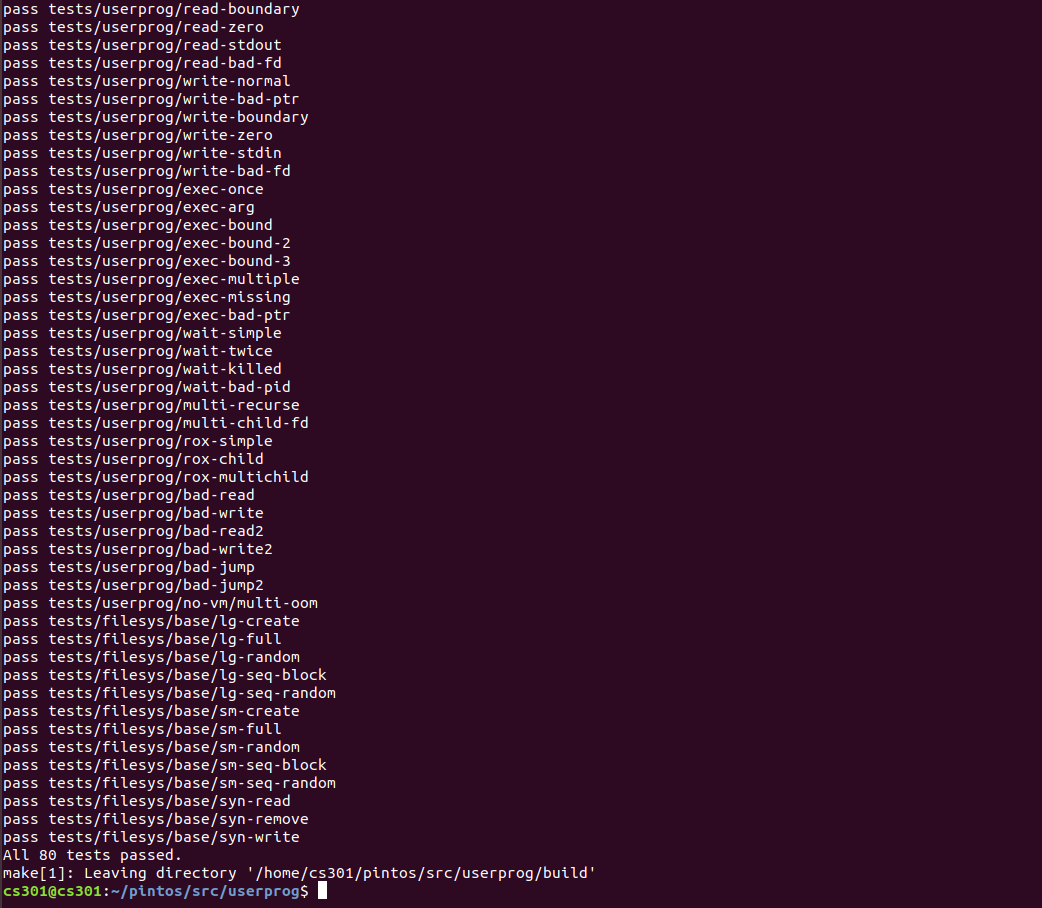
OutCome of the Assignment
- Userprog: